The beautiful chaos of open source development has many implications. It requires a level of cooperation that perhaps goes beyond that which we find in the ordinary workplace. Open source development requires collaboration, and constant communication.
At times, it's a struggle to maintain a good level of communication. This is especially true when the contributors are separated by thousands of miles, and have a wide variety of schedules. But communication in open source development is crucial. A lack of communication results in unnecessary emergencies, and can ultimately mean the difference between success and failure in an open source software development project.
Currently, I'm anxious about how to approach the challenges of these next few days, as we make the final preparations for deploying surveys. Ordinarily, I'd like to be testing, optimizing, and generally winding down development at the 11th hour before deploying a feature.
However, it's surprisingly easy to find yourself in "putting out fires" mode at these times, which can be a scary place to be, considering that last minute changes are often precursors to a variety of problems that can end up affecting the end user experience.
Part of the reason I find myself in this situation is do to my own relative inexperience, and my inability to anticipate what features and code organization would be needed and desired. Being a newcomer to Melange development, I'm often unsure of design decisions and end up implementing a feature that either don't match the functional or structural needs, and either me or someone else will have to go back and make changes after dependencies and documentation have already been created.
If I did a better job of communicating specifications for all my work, I probably would have saved a good deal of development time.
While in "putting out fires" mode, these design decisions can be even more difficult to make, since there is a great incentive to do things the quick and ugly way.
For instance, now that the Survey class has been subclassed as ProjectSurvey and GradingProjectSurvey, there needs to be a way for a user creating a survey to specify whether the survey is a Survey, a ProjectSurvey, or a GradingProjectSurvey.
The dynaform workflow does not suggest an obvious solution, and there are at least several possible implementations. Earlier tonight, I implemented one solution and then realized that my solution, while convenient from a short-term development perspective, would certainly simply lead to more changes and more "putting out fires" mode, and would result in a net-loss of time. So I decided to start over, with a different approach.
The new approach is to confirm my decisions through communication, rather than solely self-confirmation. This approach may require some humility and patience, but it's surely better than staying up all night banging my head against the proverbial wall.
Knowing that Melange developers are all intelligent and friendly to the Nth degree, I'm certain that all have it within us to strive to be more communicative and receptive to communication, and ultimately create a better product in the process.
A quick update about developments for the newsfeed feature -- the changes in the last few days have mostly been style guide changes. Since we've been sweeping through the survey code and updating style, I've used the opportunity to also get my newsfeed code up to style guide standards. I've segregated the news feed into a hibernating working branch now that there's more direct interaction between the soc hg trunk and my personal github repo. Since newsfeed requires changes in many view and logic files in addition to distinct "newsfeed.py" type modules, it's far easier for me to not even attempt to keep these changes in my survey-related work.
Tuesday, June 30, 2009
Monday, June 29, 2009
Statistic module - 4th and 5th week update
First of all, let me apologize for not updating the blog a week ago. I know there are no excuses - I was just putting off this task so many times that the whole week passed.
To begin with, I will try to describe my 'two-weeks-ago' update.
First of all, I added support for some more sophisticated statistics. The question is how to define which statistics are in this group? At first, let us take a look at a simple statistic that had been already correctly counted. For example Students Per Degree. Collection process for such a statistic looks like this: we have static list of choices for degrees ('undergraduate', 'master', 'PhD') and we iterate through all student entities (in batches of course because of Google Application Engine limitations), for each entity we check degree field and increase value in the appropriate basket. But unfortunately we do not know the list of choices before starting collection. Let us take a look at statistic like Applications Per Students. In this case we could also have static choices (numbers from 1 through 20, because every student may submit up to 20 application) and gather data by iterating through all student entities, and for each student iterate through all student proposals entities, check how many of them belongs to the student. Anyway, it would be at least as inefficient as bubble sort for large data input - its complexity could be
O(proposals * students).
Of course there is better way: to have a list of all students as choices, iterate through student proposals and for each of them increase number connected with the student in scope. There is just one problem: we do not have the list of all students at the beginning, but we have a simple walk-around: at the beginning list of choices is empty and we add students to this list dynamically. When we process a single proposal, we check if the student in scope is already in the list. If so, we increase his number by one, otherwise we add him and set his number to one. This is quite a smooth way. Of course I know this algorithm is not linear depending on number of proposals, because we look up for a student in dictionary, but in worst case it works like
O(proposals * log(_students_)),
where _students_ is a number of students who submitted at least one proposal, but this attempt is better than the first one.
Anyway, it still has a disadvantage: we have no information about the students who did not submit any proposals - and there is certainly a bunch of them. For other similar tasks this problem is not so substantial. For example Applications Per Organization: we may assume that each organization receives at least one proposal; for Students Per Program we may also assume that for each program (at least hosted by Google:-) someone registers himself, and so on. Nonetheless, Mario and I decided that all statistics should be fully covered.
Therefore, the statistics, which we do not know their full list of choices for, will be collected in the following way: first, we collect full list of choices (also in batches, because their number can be large) and after that we collect actual data. For example, let us consider Applications Per Student again: first we iterate through all student entities and then, having a full list of students, we iterate through proposals and mach proposals with the students.
Anyway, this way has not been merged into our repository yet. Collecting statistic this way in batches would be very awkward, because the number of batches automatically increases. Anyway, it is ready and may be merged quickly after a conversation with mentors and/or other developers.
Some other things which were achieved during that week includes: creating standard views for statistic entities, like create, list, delete; adding support for a few new statistics.
And last but not least, Mario and made some important decisions. Firstly, Mario set up Issue Tracker on our bitbucket repository. Secondly, we decided to organize daily meetings. Thirdly, we postponed abstraction of statistics until we add support for statistics for surveys.
And now, let me move on to the very last week. First of all, I was sick on Thursday and Friday so I could not finally do everything that I had planned.
The most important thing that has been done is that statistics are now collected using Task Queue API. I tried to use this API wisely and make the code at least a little bit reusable, because this API will be probably useful also for other problems that Melange is to encounter in the future. I am going to describe my solution in the wiki and on dev list. It would be great if I got some feedback so as to improve it. The most important thing about it is that we can divide a long task into smaller subtasks and then start a task. When we execute one task and find that the whole task is not completed, we may repeat the same task or start a new one. Statistic collection may be just an example, but as we know, they are collected in batches. So we start a task which collects the first batch saves its data and because the whole collection is not completed, it restarts the task. User is obligated just to turn on the first task and does not have to click several times.
This week I also started getting involved in Java Script side of the module. Mario is the one who created the whole skeleton and I had to understand his conception. Until now I have taken a good look at his code and gone through a jQuery tutorial . Today Mario briefly described me the skeleton (thank you for that!:) and I am going to write some code on my own very soon.
To begin with, I will try to describe my 'two-weeks-ago' update.
First of all, I added support for some more sophisticated statistics. The question is how to define which statistics are in this group? At first, let us take a look at a simple statistic that had been already correctly counted. For example Students Per Degree. Collection process for such a statistic looks like this: we have static list of choices for degrees ('undergraduate', 'master', 'PhD') and we iterate through all student entities (in batches of course because of Google Application Engine limitations), for each entity we check degree field and increase value in the appropriate basket. But unfortunately we do not know the list of choices before starting collection. Let us take a look at statistic like Applications Per Students. In this case we could also have static choices (numbers from 1 through 20, because every student may submit up to 20 application) and gather data by iterating through all student entities, and for each student iterate through all student proposals entities, check how many of them belongs to the student. Anyway, it would be at least as inefficient as bubble sort for large data input - its complexity could be
O(proposals * students).
Of course there is better way: to have a list of all students as choices, iterate through student proposals and for each of them increase number connected with the student in scope. There is just one problem: we do not have the list of all students at the beginning, but we have a simple walk-around: at the beginning list of choices is empty and we add students to this list dynamically. When we process a single proposal, we check if the student in scope is already in the list. If so, we increase his number by one, otherwise we add him and set his number to one. This is quite a smooth way. Of course I know this algorithm is not linear depending on number of proposals, because we look up for a student in dictionary, but in worst case it works like
O(proposals * log(_students_)),
where _students_ is a number of students who submitted at least one proposal, but this attempt is better than the first one.
Anyway, it still has a disadvantage: we have no information about the students who did not submit any proposals - and there is certainly a bunch of them. For other similar tasks this problem is not so substantial. For example Applications Per Organization: we may assume that each organization receives at least one proposal; for Students Per Program we may also assume that for each program (at least hosted by Google:-) someone registers himself, and so on. Nonetheless, Mario and I decided that all statistics should be fully covered.
Therefore, the statistics, which we do not know their full list of choices for, will be collected in the following way: first, we collect full list of choices (also in batches, because their number can be large) and after that we collect actual data. For example, let us consider Applications Per Student again: first we iterate through all student entities and then, having a full list of students, we iterate through proposals and mach proposals with the students.
Anyway, this way has not been merged into our repository yet. Collecting statistic this way in batches would be very awkward, because the number of batches automatically increases. Anyway, it is ready and may be merged quickly after a conversation with mentors and/or other developers.
Some other things which were achieved during that week includes: creating standard views for statistic entities, like create, list, delete; adding support for a few new statistics.
And last but not least, Mario and made some important decisions. Firstly, Mario set up Issue Tracker on our bitbucket repository. Secondly, we decided to organize daily meetings. Thirdly, we postponed abstraction of statistics until we add support for statistics for surveys.
And now, let me move on to the very last week. First of all, I was sick on Thursday and Friday so I could not finally do everything that I had planned.
The most important thing that has been done is that statistics are now collected using Task Queue API. I tried to use this API wisely and make the code at least a little bit reusable, because this API will be probably useful also for other problems that Melange is to encounter in the future. I am going to describe my solution in the wiki and on dev list. It would be great if I got some feedback so as to improve it. The most important thing about it is that we can divide a long task into smaller subtasks and then start a task. When we execute one task and find that the whole task is not completed, we may repeat the same task or start a new one. Statistic collection may be just an example, but as we know, they are collected in batches. So we start a task which collects the first batch saves its data and because the whole collection is not completed, it restarts the task. User is obligated just to turn on the first task and does not have to click several times.
This week I also started getting involved in Java Script side of the module. Mario is the one who created the whole skeleton and I had to understand his conception. Until now I have taken a good look at his code and gone through a jQuery tutorial . Today Mario briefly described me the skeleton (thank you for that!:) and I am going to write some code on my own very soon.
GSoC09: Statistics module 4th weekly report: dashboard!
While midterm is approaching, this week has been very productive to start integrating Javascript and Python ends together and begin producing the Ajaxy dashboard for statistics module, pushing almost all ehancement that were planned. It also helped me a lot to introduce me better on the Python end, at least for basic tasks. Furthermore, I've continued helping with JS code review for survey module and helping fixing Melange bugs.
So, here the story: starting from Tuesday, I've set up my Windows partition to try to help with Organization home Google map bug, but at the end I was not successful as I couldn't reproduce the bug itself in my box :( I've then created the dashboard model, logic, view and template for the Statistics dashboard page. After helping with another code review for survey module, I've fixed (well, almost fixed, discussion is still ongoing) Melange issue 645.
After that, I worked on producing the skeleton for the Dashboard page, borrowing and taking inspiration from How to mimic iGoogle interface Nettuts tutorial (without widgets moving at first), so building bases to have the widgets created dinamically (in that way, we can retrieve settings for each chart from the Python end) and also added an OSX style stack menu (even if we will drop it out, as it's not so homogeneous with the rest of Melange application GUI).
To make the widgets inside the dashboard moving, I had to integrate sortable and draggable extensions of jQuery UI. But these were already been integrated by survey module, so I thought to merge with the main branch instead of doing something duplicate, and that introduced me on using kdiff3. At the end of the merge, and after some use of Javascript, I had the widgets finally moving on the dashboard!
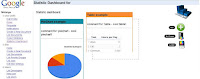
On Friday, after another code review for Survey module Javascript side, I started a thread with Daniel Diniz (ajaksu) about Javascript style, and found it very very interesting and full of new ideas. That is the beauty of open source! :) Discussion need to be continued, but we came with some improvements of Javascript style guide wiki page.
The same day I worked on bug fixing dashboard, because it seemed not to work on Safari and IE. I've then found that I was passing to an anonymous function a variable called class, which turns to be a reserved keyword for both Safari and IE... renamed it to _class and all begun to work!
On Saturday I kept trying to work on Melange issue 645, finding also a good article about event capturing (which is somewhat the opposite of event delegation).
On Sunday, at the end, I've created model, logic and view skeleton for charts in Python (thanks Lennie ^__^), which will store and retrieve single chart instances for every user. I used then jQuery thickbox to display a "new chart" window, beginning to integrate Javascript code with Python to have a list of available statistics data (made available by Daniel Hans in a JSON object to be retrieved asynchronously) to be injected in a widget in the dashboard.
Things are going to be exciting next week, when we'll probably come with more interaction between Javascript and Python ends and see finally everything beginning to work!
So, here the story: starting from Tuesday, I've set up my Windows partition to try to help with Organization home Google map bug, but at the end I was not successful as I couldn't reproduce the bug itself in my box :( I've then created the dashboard model, logic, view and template for the Statistics dashboard page. After helping with another code review for survey module, I've fixed (well, almost fixed, discussion is still ongoing) Melange issue 645.
After that, I worked on producing the skeleton for the Dashboard page, borrowing and taking inspiration from How to mimic iGoogle interface Nettuts tutorial (without widgets moving at first), so building bases to have the widgets created dinamically (in that way, we can retrieve settings for each chart from the Python end) and also added an OSX style stack menu (even if we will drop it out, as it's not so homogeneous with the rest of Melange application GUI).
To make the widgets inside the dashboard moving, I had to integrate sortable and draggable extensions of jQuery UI. But these were already been integrated by survey module, so I thought to merge with the main branch instead of doing something duplicate, and that introduced me on using kdiff3. At the end of the merge, and after some use of Javascript, I had the widgets finally moving on the dashboard!

On Friday, after another code review for Survey module Javascript side, I started a thread with Daniel Diniz (ajaksu) about Javascript style, and found it very very interesting and full of new ideas. That is the beauty of open source! :) Discussion need to be continued, but we came with some improvements of Javascript style guide wiki page.
The same day I worked on bug fixing dashboard, because it seemed not to work on Safari and IE. I've then found that I was passing to an anonymous function a variable called class, which turns to be a reserved keyword for both Safari and IE... renamed it to _class and all begun to work!
On Saturday I kept trying to work on Melange issue 645, finding also a good article about event capturing (which is somewhat the opposite of event delegation).
On Sunday, at the end, I've created model, logic and view skeleton for charts in Python (thanks Lennie ^__^), which will store and retrieve single chart instances for every user. I used then jQuery thickbox to display a "new chart" window, beginning to integrate Javascript code with Python to have a list of available statistics data (made available by Daniel Hans in a JSON object to be retrieved asynchronously) to be injected in a widget in the dashboard.
Things are going to be exciting next week, when we'll probably come with more interaction between Javascript and Python ends and see finally everything beginning to work!
GSoC 2009:GHOP - Fifth Week Status update!
Hello everyone,
It has been more than a month since the coding season started, quite a bit of progress is expected at least by now :). Hopefully I have made enough progress except for those few days lost in the schedule. Last week seems like the most productive week for me till now from the day coding season started.
I have been able to add the following features: Org Admins can now create tasks, Mentors too can create tasks. Org Admins can publish their own tasks and they can approve the tasks created by mentors. Also they can approve and publish the tasks created by mentors in one go. I am right now working bulk approve and publishing of tasks by Org Admins, which should be over by today. (Note of deletion of tasks is not enabled yet for Org Admins or Mentors, will work on it this week if time permits, if not I will postpone it to post mid-term since getting the core functionality done has been the priority for now :) ).
I will be pushing the code to my demo instance http://melange-madhusudancs.appspot.com and will be pushing all the patches to my patch queue at http://bitbucket.org/madhusudancs/melange-mq/ by tomorrow. Also those who test the demo instances please feel free to report issues/bugs in the issue tracker of my patch queue at bitbucket, http://bitbucket.org/madhusudancs/melange-mq/issues/ . Also I request you all to help me test tasks creation and editing by Org Admins and Mentors.
This week I will mostly concentrate on integrating taggable-mixin with tasks for tags. It has been pending from a long time now, I cannot delay it any further. Along with taggable-mixin I will be working on student side of Tasks work, Claim tasks, Withdraw claim among other things.
It has been more than a month since the coding season started, quite a bit of progress is expected at least by now :). Hopefully I have made enough progress except for those few days lost in the schedule. Last week seems like the most productive week for me till now from the day coding season started.
I have been able to add the following features: Org Admins can now create tasks, Mentors too can create tasks. Org Admins can publish their own tasks and they can approve the tasks created by mentors. Also they can approve and publish the tasks created by mentors in one go. I am right now working bulk approve and publishing of tasks by Org Admins, which should be over by today. (Note of deletion of tasks is not enabled yet for Org Admins or Mentors, will work on it this week if time permits, if not I will postpone it to post mid-term since getting the core functionality done has been the priority for now :) ).
I will be pushing the code to my demo instance http://melange-madhusudancs.appspot.com and will be pushing all the patches to my patch queue at http://bitbucket.org/madhusudancs/melange-mq/ by tomorrow. Also those who test the demo instances please feel free to report issues/bugs in the issue tracker of my patch queue at bitbucket, http://bitbucket.org/madhusudancs/melange-mq/issues/ . Also I request you all to help me test tasks creation and editing by Org Admins and Mentors.
This week I will mostly concentrate on integrating taggable-mixin with tasks for tags. It has been pending from a long time now, I cannot delay it any further. Along with taggable-mixin I will be working on student side of Tasks work, Claim tasks, Withdraw claim among other things.
Subscribe to:
Posts (Atom)

